タフツ大学のニューロシンボリックAI、エネルギー99%削減でロボット成功率95%を出した
99%。この数字が出てきたとき、最初は読み違いかと思った。
トレーニング時のエネルギー消費が従来モデル比で99%削減、推論時も95%削減、その上でロボットタスクの成功率が34%から95%に跳ね上がる。省エネで性能も上がるというのは、普通は成立しない話だ。どちらかを犠牲にするのがエンジニアリングの常識だった。タフツ大学のMatthias Scheutz教授らが発表した研究は、その常識を正面から崩している。
なぜ「省エネで高精度」が成立したのか
従来のロボット制御用AIの多くは、ビジョン・言語・行動を一つの大規模ニューラルネットワークで処理するアーキテクチャを取る。Vision-Language-Action(VLA)モデルと呼ばれるこの設計は、膨大なデータと計算資源を必要とする。GPUで数日から数週間かけてトレーニングし、推論のたびに重いネットワーク全体を動かす。
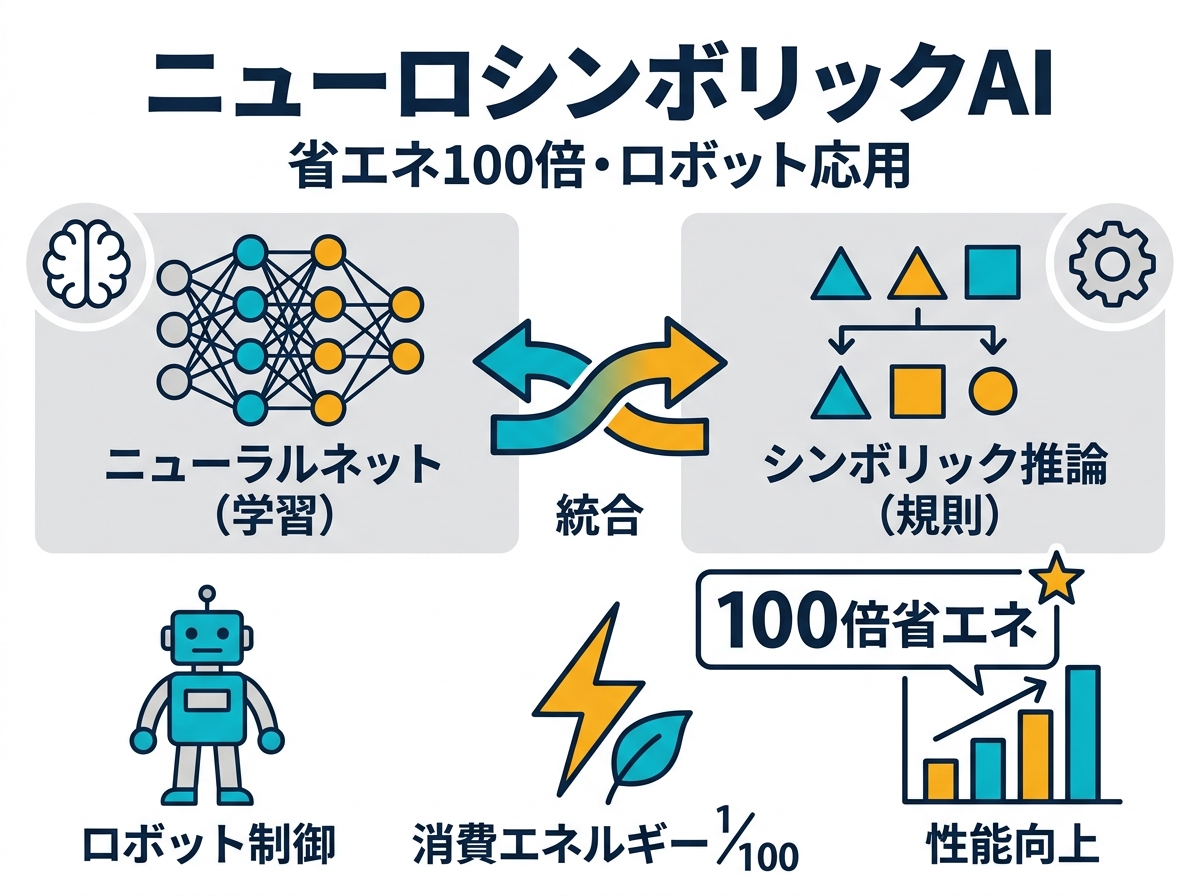
Scheutz教授らのアプローチは違う。ニューロシンボリックAIとは、ニューラルネットワーク(学習と知覚)と記号論理(推論と計画)を組み合わせたハイブリッド構造だ。知覚系には軽量なネットワークを使い、推論と行動計画は記号的なシステムに担わせる。役割が分担されているので、全体を一つの巨大なモデルで動かす必要がない。
結果として、必要な計算量が劇的に減る。トレーニング時のデータ量も小さくて済む。記号ロジックの部分は学習ではなく定義するものなので、そもそもデータを消費しない。これがエネルギー削減の仕組みだ。
ハノイの塔で何が起きたか
研究チームが評価に使ったタスクの一つが「ハノイの塔」だ。棒の間でブロックを決まった手順で積み替えるパズル的な作業で、ロボットがルールに従った多ステップの計画を正確に実行できるかを測るのに適している。
従来のVLAモデルはこのタスクで成功率34%だった。3回に1回しかうまくいかない。Scheutz教授らのニューロシンボリックモデルは同じタスクで95%を記録した。成功率がほぼ3倍になった。
この差は何に由来するのか。VLAモデルは「それらしい次の動作」を確率的に出力するが、手順全体のロジックを保持しているわけではない。途中でズレが生じたとき、修正の根拠がない。一方、記号ロジックを持つニューロシンボリック系は「今どのステップにいて、次に何をすべきか」を明示的に管理できる。複数ステップにまたがるタスクほど、この差が出やすい。
VLAモデルとの比較で見えてくること
現在、ロボットAI開発の主流はGoogleのRT-2やOpenVLAのようなVLAモデルだ。エンドツーエンドで学習できるため、新しい環境への汎化性能が高いとされる。研究コミュニティでも資本の面でも、こちらへの投資が圧倒的に大きい。
それに対してニューロシンボリックアプローチは、かつて「第1次AIブーム」の流れを汲む古い枠組みとして、ディープラーニング全盛の時代に影が薄くなっていた。Scheutz教授の研究は、そのアプローチを現代のロボティクスに接続し直したとも言える。
ただ、「VLAより優れている」と結論づけるのは早い。VLAモデルの強みは多様な視覚入力への対応力と、明示的にルールを書かなくても動作する柔軟性だ。ニューロシンボリック系はルールが事前に定義できるタスクで強く、予期しない状況への対応では別の課題が残る可能性がある。
まだ残る問いとフィールドへの距離
このアーキテクチャがロボット制御の主流になるかどうかは、実験室の外で何ができるかにかかっている。
現実の工場や倉庫では、想定外の物体、照明条件の変化、人間の不規則な動作など、ルールに収まらない状況が次々に発生する。記号ロジックベースのシステムが「想定外」にどこまで対応できるかは、ハノイの塔の結果だけでは見えない。
エネルギー面での優位性は疑いようがない。データセンターの電力消費がここまで社会問題化しているなかで、推論コストが95%下がるというインパクトは純粋に大きい。特に、エッジ環境(クラウドに頼れない現場でのリアルタイム処理)への応用は、このアーキテクチャが得意とする領域と重なる。
発表から読み取れる範囲では、ハードウェア要件や実環境での評価についての詳細はまだ少ない。学術発表のプレスリリースという性質上、数字が最も映えるシナリオで評価されている可能性も念頭に置いておく必要がある。それでも、「効率と精度はトレードオフ」という前提を揺さぶる結果を出したことの意味は小さくない。
Sources: