
AI訓練データ大手Mercorへのサイバー攻撃——LiteLLMサプライチェーン侵害で4TBの「学習の秘密」が流出危機
AIモデルの性能を左右する「訓練データ」を直接狙ったサイバー攻撃が起きた。
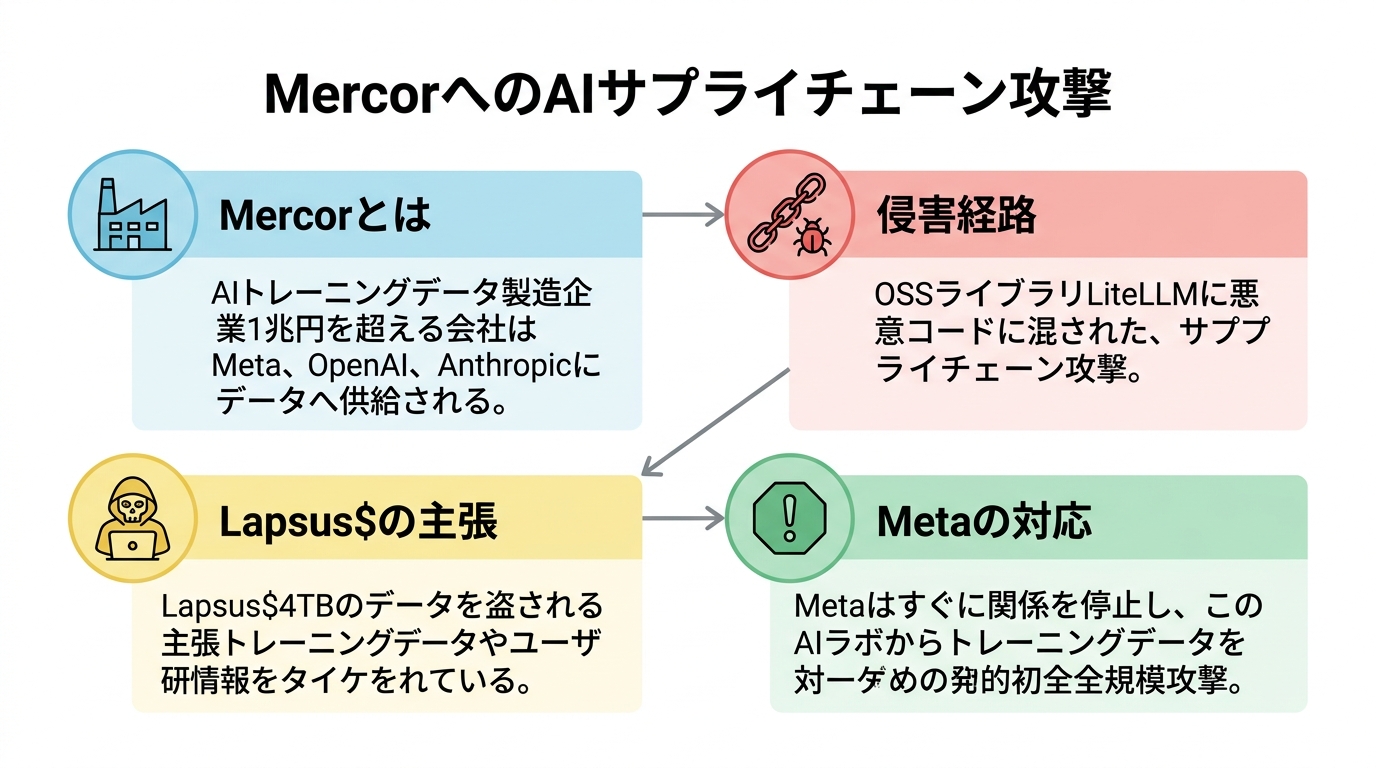
2026年3月末、人材マッチングおよびAI訓練データ事業を手がけるMercorが、重大なセキュリティインシデントを公表した。侵害の入口となったのは自社開発のシステムではない。世界中のAI開発者が使うオープンソースライブラリ「LiteLLM」への依存——つまりソフトウェアサプライチェーンを経由した攻撃だった。ハッカー集団Lapsus$は4TBのデータ窃取を主張し、Metaは関係停止を即座に決定。AIラボの訓練データという競争機密の核心が、初めて本格的な攻撃の標的となった。
Mercorとは何者か——「AIの工場」という位置づけ
事件の重大性を理解するには、まずMercorがAIエコシステムの中でどういう役割を担っているかを知る必要がある。
Mercorは当初、AIを活用した採用プラットフォームとして2023年に創業した。学生・エンジニア・研究者らのスキルプロファイルを構築し、企業とマッチングするサービスだ。しかしその事業モデルは急速に拡張した。登録する高スキル人材のプールを活用して、主要AIラボ向けの「RLHF(人間フィードバックに基づく強化学習)データ」の製造を請け負うようになったのだ。
直近の評価額は100億ドル(約1.5兆円)に達しており、OpenAI・Meta・Anthropicといった主要プレイヤーとの取引関係が報じられている。Meta向けには、Llamaシリーズのファインチューニングに用いる高品質な対話データを継続供給していたとされる。要するにMercorは、最先端AIモデルの「学習素材」を製造する工場だ。その工場への不法侵入が今回起きた。
侵害経路:LiteLLMへのサプライチェーン攻撃
攻撃者は正面玄関ではなく、裏口から入ってきた。
LiteLLMはOpenAI・Anthropic・Google Geminiなど100以上のLLM APIへの統一インターフェースを提供するPython製オープンソースライブラリで、GitHubのスター数は3万を超える人気プロジェクトだ。Mercorはこのライブラリを内部のAIインフラに組み込んでいた。
TechCrunchの報道によれば、攻撃者はLiteLLMのリポジトリに悪意あるコードを混入させることで、このライブラリに依存しているシステムへのバックドアを確保した。MercorのエンジニアリングチームはLiteLLMのアップデートを通常の業務フローで取り込んでおり、結果として侵害コードが本番環境に展開された。
LiteLLMの開発元BerriAIは侵害を確認し、問題のあるコミットを除去したと説明している。しかしMercorが「汚染されたバージョン」を実行していた期間中に、どの範囲のシステムへのアクセスが可能だったかは依然として調査中だ。ここで率直に言えば、サプライチェーン攻撃の厄介さはまさにこの点にある——使用中のライブラリが「いつ、どのバージョンから」侵害されているかを、ユーザー側が即座に判断するのはほぼ不可能だ。
Lapsus$の主張と4TBという数字
侵害発覚後、犯行声明を発したのはLapsus$グループだ。
Lapsus$は2021〜2022年にNVIDIA・Microsoft・Samsung・Okta・Rockstar Gamesなどへの侵害で世界的な注目を集めたハクティビスト集団で、主要メンバーの多くはティーンエイジャーだった。その後主要メンバーが逮捕・起訴されたが、同名を冠するグループは活動を継続している。
今回Lapsus$が主張するのは「4TBのデータ窃取」だ。その内容として具体的に言及されているのは、Mercorのユーザープロファイルデータ(氏名・職歴・スキル評価・給与情報など)と、AIラボ向けに製造・保存されていた訓練データセットだ。
4TBという数字が本当だとすれば、相当なボリュームになる。ただし、この主張は現時点でMercor側が全面的に認めているわけではない。Mercorの公式声明は「不正アクセスがあったことは確認された」としつつ、具体的なデータ規模や種別については「調査中」という立場だ。Lapsus$のような集団が実際の被害を誇張するケースも歴史的に存在するため、4TBという数字は慎重に扱う必要がある。
Metaの即時停止決定とその意味
今回の事件で最も動きが速かったのはMetaだった。
TNWの報道によれば、Mercorとの侵害発覚を受けてMetaはほぼ即座に取引の停止を決定した。Llamaシリーズの継続開発に向けて進めていたとされる訓練データの調達プロジェクトを一時凍結し、供給ルートを精査する方針に転換したという。
この決定が示唆することは大きい。訓練データのサプライヤーが侵害されたとき、そのデータを使って学習したモデルには何が起きるか——という問いが、一気に現実の問題として浮上したからだ。AIモデルの訓練プロセスは通常、外部から提供されたデータをそのまま使う。悪意あるデータが混入していればモデルのふるまいが意図せず変化するリスク(データポイズニング)があり、また窃取されたデータに機密情報が含まれていれば競合他社や悪意ある第三者への情報漏洩が起きる。Metaが停止を選んだのは、こうしたリスクを「調査が終わるまで取り込まない」という判断だ。
OpenAIとAnthropicについては、本稿執筆時点で公式なコメントや取引停止に関する報告は出ていない。しかしMercorとの取引関係が報じられている以上、両社の対応も注目される。
AIサプライチェーンという新たな攻撃面
今回の事件を、単なる「データ漏洩事故」として捉えるのは浅い見方だ。
従来のサイバーセキュリティの文脈では、サプライチェーン攻撃とは主にソフトウェアのビルドパイプラインや更新機構を狙うものとして理解されてきた。SolarWinds事案(2020年)やXZ Utilsバックドア事案(2024年)がその代表例だ。今回のMercor・LiteLLM事案は、これをAI特有のレイヤーに拡張したケースと見ることができる。
AI開発のサプライチェーンには、少なくとも三つの段階がある。第一はモデルアーキテクチャやフレームワーク層(PyTorch・JAXなど)。第二がLiteLLMのような推論・ルーティング層。そして第三が今回標的となった訓練データの調達・製造層だ。これまで攻撃が集中してきたのは主に第一・第二層だったが、第三層が本格的な標的になり始めた。
Mercorが担っていた役割は「高品質な人間によるフィードバックデータを製造・供給する」というものだ。この層を掌握されると、AIラボのモデル開発スケジュールへの影響、競合他社への訓練データ流出、そしてより高度なシナリオとして「汚染データの注入によるモデル品質の意図的な劣化」といったリスクが生じる。最後のリスクは現時点での証拠はないが、将来の攻撃形態として議論が始まっている。
問われるオープンソース依存の構造
LiteLLMがサプライチェーン攻撃の入口となったことは、AI開発エコシステム全体の構造的な問いを提起する。
AI開発の現場では、オープンソースライブラリへの依存は当たり前だ。HuggingFaceのtransformers、LangChain、そしてLiteLLMのようなツールは、数千の商用製品・サービスの基盤に組み込まれている。しかしこれらのリポジトリへのコントリビューション審査やリリースの署名検証は、プロジェクトによって精度が大きく異なる。LiteLLMのケースでは、悪意あるコミットが本番環境に到達するまで検知されなかった。
個人的に気になるのは、AIラボ各社がサプライヤーのセキュリティ体制をどこまで評価・監査していたかという点だ。Mercorが100億ドル企業に成長した速度を考えると、セキュリティ成熟度の評価がビジネス拡大に追いついていなかった可能性がある。同時に、発注側のAIラボが「訓練データのサプライヤー選定基準にセキュリティ監査を含めていたか」も問われる。LiteLLMのような広く使われるオープンソースプロジェクトについては、主要利用企業が協調してセキュリティ審査を支援する仕組みを整備する必要がある。
AIの競争がデータの質と量に依存する構造である以上、訓練データの製造・流通プロセスは今後さらに重要な攻撃対象となっていく。Mercorへの攻撃は、その警告射撃として機能した事件かもしれない。
Sources: