
Mistral AI「Voxtral TTS」公開——40億パラメータで実現するオープンな音声合成
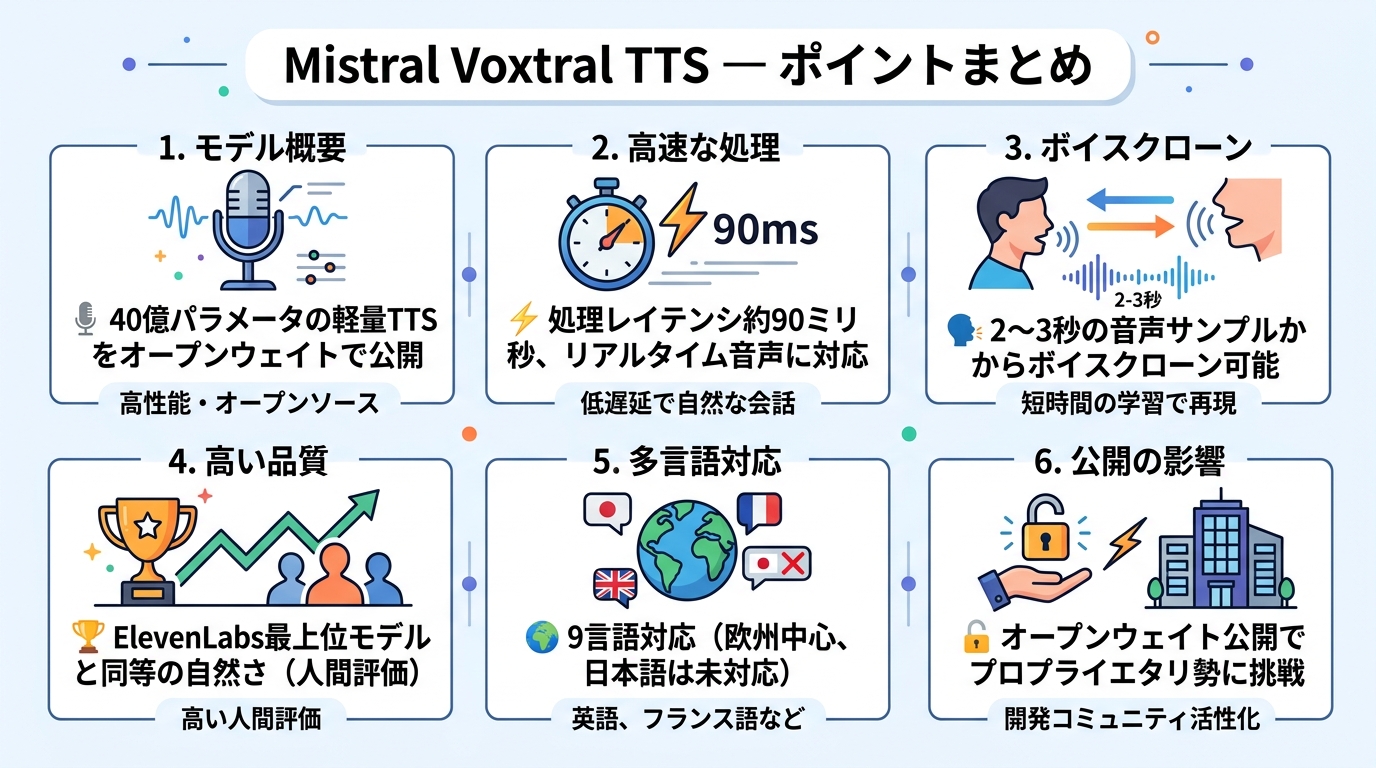
フランスのMistral AIが3月26日、テキスト読み上げ(TTS)モデル「Voxtral TTS」をオープンウェイトで公開した。40億パラメータという軽量さながら、ElevenLabsの最上位モデルと同等の自然さを達成したという。わずか2〜3秒の音声サンプルから話者の声をクローンでき、処理レイテンシは約90ミリ秒。Mistral AIにとって、音声生成分野への初参入となる。
率直に言って、このリリースには驚いた。Mistral AIはLLM(大規模言語モデル)の会社だと思っていたからだ。音声合成の市場にオープンウェイトで殴り込みをかけてくるとは、ElevenLabsやAmazon Pollyといったプロプライエタリ勢にとって無視できない動きだろう。
40億パラメータの軽量モデル——何ができるのか
Voxtral TTSの中核スペックを整理する。
モデルサイズは40億(4B)パラメータ。GPT-5クラスのLLMが数千億パラメータであることを考えると、極めて小さい。この軽量さの恩恵は明確で、オンデバイスやオンプレミスでの実行が現実的になる。クラウドAPIに音声データを送る必要がなくなるため、プライバシー要件が厳しい医療・金融・法務領域での活用が見込まれる。
対応言語は9つ。英語、フランス語、ドイツ語、スペイン語、オランダ語、ポルトガル語、イタリア語、ヒンディー語、アラビア語をカバーする。日本語や中国語が含まれていない点は残念だが、Mistral AIの拠点がフランスであることを考えれば、欧州言語の充実は当然の優先順位だろう。
最も目を引くのは、2〜3秒の音声サンプルから話者の声質・感情・アクセントをクローンできる機能だ。従来のボイスクローニングは数十秒から数分のサンプルを必要とするものが多かった。この短さは、実運用での導入ハードルを大幅に下げる。
ElevenLabsとの比較——人間評価で何が見えたか
Mistral AIは人間評価の結果を公表しており、その数字は興味深い。
ElevenLabs Flash v2.5との比較では、Voxtral TTSが自然さ(naturalness)で優位に立った。Flash v2.5はElevenLabsのリアルタイム向け軽量モデルであり、レイテンシ重視の設計だ。同じ土俵で勝っているのは、Voxtral TTSの90ミリ秒という処理速度を考えれば十分にインパクトがある。
一方、ElevenLabsのフラッグシップであるv3との比較では「同等(parity)」という評価。つまりVoxtral TTSは、ElevenLabsの最高品質モデルと並ぶ自然さを持ちながら、モデルの重みが完全に公開されているということになる。この非対称性は大きい。
ただし冷静に見る必要もある。人間評価の条件——対象言語、評価者の母語、テキストの種類——は公開情報が限られており、あらゆる条件で同等かどうかは断言できない。実際に試してみないと分からない部分は残る。
オープンウェイトがもたらす構造変化
Voxtral TTSのモデルウェイトはHugging Faceで「mistralai/Voxtral-4B-TTS-2603」として公開されている。オープンライセンスでの提供であり、企業は自社環境にダウンロードしてローカルで実行できる。
この公開方針が持つ意味は、技術的な興味を超えている。ElevenLabsやAmazon Pollyといった既存の音声合成サービスは、APIベースの従量課金モデルで事業を成り立たせてきた。音声データをクラウドに送り、処理結果を返す。利用量が増えればコストも増える。
Voxtral TTSはその構造を根本から揺さぶる。ローカルで動かせるなら、APIの利用料は発生しない。音声データが外部サーバーに送信されることもない。顧客データの音声化やコールセンターの自動応答など、プライバシーが特に重視される用途で、企業がプロプライエタリAPIを選ぶ理由が一つ消えた。
個人的には、LLMの世界でMeta「Llama」が果たした役割と重なって見える。オープンウェイトの高品質モデルが登場すると、プロプライエタリ勢は「品質」だけでは差別化しにくくなり、エコシステムやサポート体制での勝負を迫られる。音声合成の市場でも同じ力学が働き始めるのではないか。
ボイスエージェント市場への波及
約90ミリ秒の処理レイテンシという数字が意味するのは、リアルタイムの音声エージェントに使えるということだ。
2025年から2026年にかけて、AIによる電話応対・カスタマーサポートの自動化が急速に進んでいる。この領域では、応答の自然さと低遅延の両立が必須条件。Voxtral TTSの90ミリ秒は、人間同士の会話における「間」の感覚——200〜300ミリ秒程度——を十分に下回る。
しかもボイスクローニング機能と組み合わせれば、企業は自社ブランドに合った声を短時間で用意できる。「うちのAIアシスタントの声」を、既存の声優音声バンクから選ぶのではなく、数秒のサンプルから生成する。カスタマイズの自由度が大きく広がる。
アクセシビリティの観点も見逃せない。視覚障害者向けのスクリーンリーダーや、多言語対応の公共案内システムなど、高品質なTTSが求められる場面は多い。オープンウェイトで提供されることで、非営利団体や教育機関がコストを気にせず導入できる道が開かれた。
Mistral AIの戦略転換——LLMの会社から「AIプラットフォーム」へ
Voxtral TTSの公開は、Mistral AIの事業領域が拡大していることを示している。
創業以来、Mistral AIはテキスト生成のLLMで存在感を示してきた。Mistral 7B、Mixtral、そしてMistral Largeと、オープンウェイト戦略を軸にOpenAIやAnthropicとの差別化を図ってきた会社だ。その同じ戦略を音声合成にも持ち込んだ格好になる。
次に来るのは画像生成か、それとも音声認識(STT)か。Voxtral TTSが「Voxtral」というブランド名を冠していることから、音声領域の製品ラインを拡充する意図は明確だろう。STTモデルがオープンウェイトで公開されれば、音声入力から音声出力までの一貫したパイプラインをローカルで構築できるようになる。
所感——「声」がオープンになる時代
Voxtral TTSの登場で最も重要なのは、「高品質な音声合成がコモディティ化し始めた」という事実だと思う。
これまで自然な音声合成は、ElevenLabsのようなスタートアップか、Google・Amazonのようなテックジャイアントだけが提供できる「プレミアム技術」だった。40億パラメータのオープンモデルがその品質に並んだことで、参入障壁が一段下がった。
もちろん課題もある。9言語という対応範囲は、グローバル展開を考えると狭い。ボイスクローニングの悪用リスク——ディープフェイク音声による詐欺やなりすまし——に対するセーフガードがどの程度組み込まれているかも、オープンウェイトであるがゆえに注視が必要だ。
それでも、テキスト生成でLlamaが果たした民主化の流れが、音声合成の領域にも到達したという感覚がある。Mistral AIがこの一手を打ったことで、ElevenLabsやAmazonがどう動くか。プロプライエタリ勢の次の手が気になるところだ。
Sources:
- Speaking of Voxtral | Mistral AI
- Mistral AI just released a text-to-speech model it says beats ElevenLabs — and it's giving away the weights for free | VentureBeat
- Mistral releases a new open source model for speech generation | TechCrunch
- mistralai/Voxtral-4B-TTS-2603 · Hugging Face
- Mistral releases an open-weights 'speaking' AI model with Voxtral TTS | SiliconANGLE