
Samsung、次世代AIメモリ「HBM4E」をGTC 2026で公開——帯域幅4.0TB/sの衝撃
2026年3月25日に開幕したNVIDIA GTC 2026で、Samsungが次世代AIメモリ「HBM4E」を初公開した。ピンあたり16Gbps、帯域幅4.0TB/sという数字は、現行のHBM4と比較しても大幅な性能向上であり、AI推論とトレーニングの両面でボトルネックとなってきたメモリ帯域幅の壁を一段引き上げるものだ。
AIモデルの巨大化が止まらない中で、演算能力ではなくメモリがシステム全体の性能を律速している——この事実は半導体業界では周知だが、一般的にはまだ十分に認識されていないように思う。HBM4Eの登場は、その状況を一変させるポテンシャルを持っている。
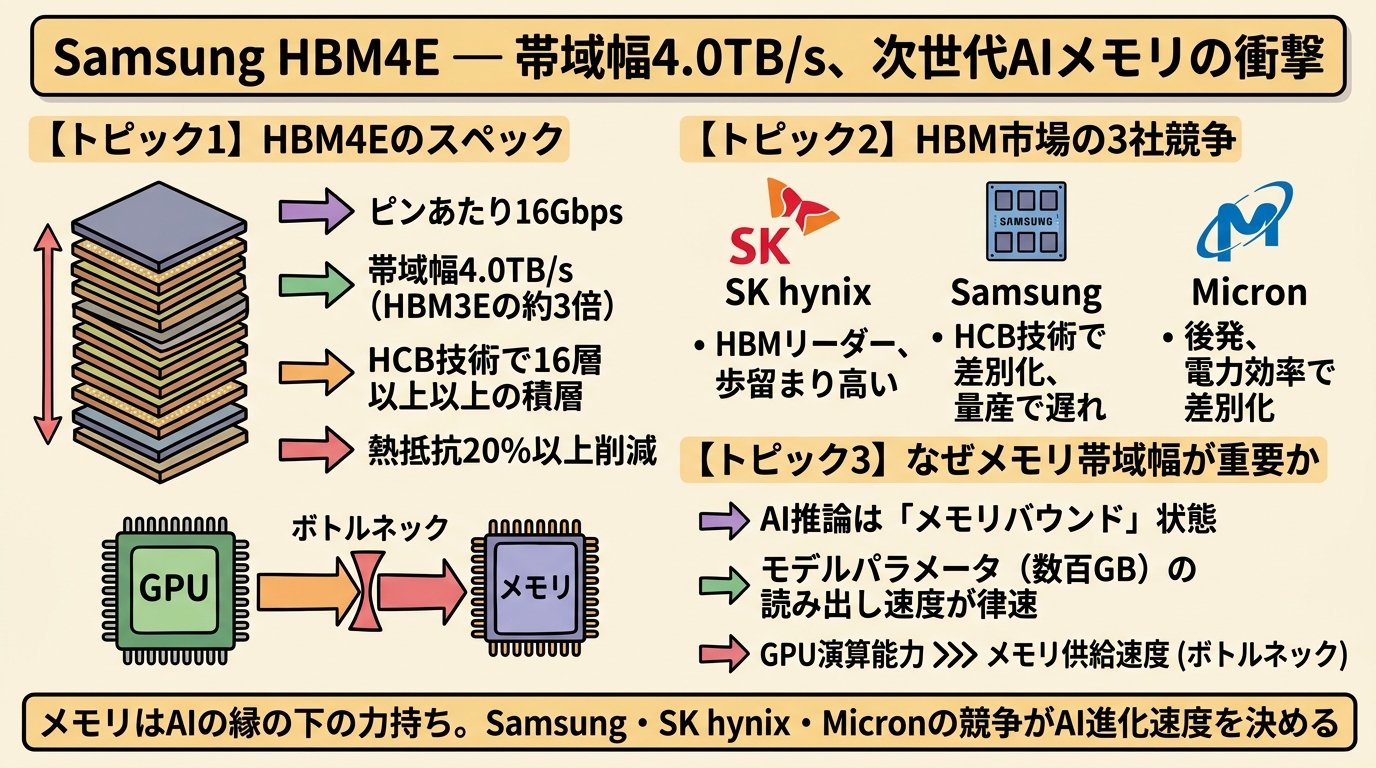
HBM4Eのスペック——何がどう変わるのか
まず、HBM4Eの技術的な位置づけを整理しよう。
HBMとはHigh Bandwidth Memoryの略で、DRAMチップを垂直に積層し、シリコンインターポーザを介してGPUやAIアクセラレータと高速接続するメモリ技術だ。世代を追うごとに帯域幅と容量が向上してきた。
HBM4Eの「E」はExtendedを意味し、HBM4の拡張版という位置づけだ。主要スペックはピンあたり16Gbps、トータル帯域幅4.0TB/s。HBM4がピンあたり8Gbpsで帯域幅2.0TB/s程度とされるから、単純に2倍の帯域幅を実現したことになる。
この帯域幅4.0TB/sという数字がどれほど異常かを説明すると、2024年に主流だったHBM3Eの帯域幅は約1.2TB/s。わずか2年で3倍以上に拡大した計算だ。メモリ技術でこのペースの進化は、率直に言って驚異的としか言いようがない。
ハイブリッド銅接合(HCB)技術の革新
HBM4Eを語る上で避けて通れないのが、Samsung独自のハイブリッド銅接合(Hybrid Copper Bonding、HCB)技術だ。
従来のHBMはマイクロバンプと呼ばれるはんだ接合で各層のDRAMチップを接続していた。しかしマイクロバンプにはサイズの限界があり、積層数を増やすと接合部の抵抗が増加し、信号品質が劣化するという問題があった。
HCB技術はこれを銅の直接接合に置き換えることで、接合ピッチ(接点間の距離)を大幅に縮小。これにより16層以上のDRAM積層が可能になった。HBM3Eが8層から12層だったことを考えると、積層数の拡大余地は大きい。
もう一つの重要な改善点が熱管理だ。SamsungはHCB技術により熱抵抗を20%以上削減したと発表している。HBMの最大の技術課題は発熱で、積層数を増やすほど内部の温度が上昇し、性能と信頼性に影響する。熱抵抗の削減は、単なるスペック改善ではなく、積層技術の実用性を根本的に担保する進歩だ。
個人的には、この熱管理の改善が今回の発表で最も重要な技術的ブレークスルーだと考えている。帯域幅の数字は分かりやすいが、それを安定的に維持するための熱設計こそが、量産段階での真の勝負どころになる。
HBM4はすでに量産中——NVIDIAのVera Rubin向け出荷
HBM4Eの話題に隠れがちだが、その前世代にあたるHBM4はすでにSamsungで量産段階に入っている。
主要な出荷先はNVIDIAで、同社の次世代プラットフォーム「Vera Rubin」に搭載される。Vera Rubinは2027年に本格展開が予定されているNVIDIAの次期フラグシップで、現行のBlackwell世代を置き換える位置づけだ。
SamsungがHBM4の量産を確保したことは、同社にとって重要な意味を持つ。HBM3E世代ではSK hynixがNVIDIAへの主要サプライヤーの座を獲得し、SamsungはNVIDIAの品質認定に苦戦したとの報道が相次いでいた。HBM4での量産開始は、この遅れを取り戻す第一歩と言える。
ただし、NVIDIAのVera Rubinプラットフォーム全体のHBM需要をSamsung単独で満たすことは難しく、SK hynixとMicronも並行してHBM4を供給する体制が構築されるとみられる。メモリ市場における3社の競争と協調は、AI半導体のサプライチェーン全体を左右する。
SK hynix、Micronとの競争構図
HBM市場はSamsung、SK hynix、Micronの3社による寡占状態にある。各社の立ち位置を整理しよう。
SK hynixはHBM市場のリーダーだ。HBM3Eで圧倒的なシェアを獲得し、NVIDIAとの緊密な関係を築いた。HBM4についても早期の量産を表明しており、Samsungの先行発表に対して技術的な自信を見せている。SK hynixの強みは歩留まり(良品率)の高さにあり、大量生産での安定性が評価されている。
Micronは3社の中では後発だが、HBM3Eでの技術水準は急速に向上している。同社はHBM4への移行を2026年後半に予定しており、HBM4E世代では独自のパッケージング技術で差別化を図る方針だ。特に電力効率の面でリードを目指すとされる。
Samsungは今回のHBM4E発表で技術的なリーダーシップを主張しているが、量産での実績がSK hynixに後れを取っている。HCB技術という独自の武器を持つものの、これが量産段階でどれだけの歩留まりを実現できるかが未知数だ。
正直なところ、技術デモの段階で「勝者」を予測するのは早計だ。HBM市場では量産能力、歩留まり、顧客との関係性が最終的なシェアを決める。Samsungの技術が優れていても、安定供給ができなければNVIDIAやAMDからの大量受注は得られない。
AI推論のボトルネック——なぜメモリ帯域幅が重要なのか
ここで、なぜHBMの帯域幅がこれほど重要なのかを解説しておきたい。
現在のAIモデル、特に大規模言語モデル(LLM)の推論処理は、計算能力ではなくメモリ帯域幅によって律速されている。これは「メモリバウンド」と呼ばれる状態だ。
LLMの推論時には、モデルのパラメータ(重み)をメモリからGPUの演算ユニットに転送する必要がある。例えばClaude Opus 4.6やGPT-5.4クラスのモデルでは、数千億のパラメータが存在し、そのデータ量は数百GBに達する。これを推論の度に読み出すため、メモリの「読み出し速度」=帯域幅がシステム全体の処理速度を決定する。
GPUの演算能力は年々向上しているが、その速度でデータを供給するメモリが追いついていない。NVIDIAの最新GPUは数千TFLOPSの演算能力を持つが、メモリが十分な速度でデータを供給できなければ、演算ユニットは空転する。これが「メモリの壁」だ。
HBM4Eの4.0TB/sという帯域幅は、この壁を押し上げる。単純計算で、800GBのモデルパラメータを200ミリ秒で読み出せることになり、推論のレイテンシ(応答時間)を大幅に短縮できる可能性がある。
MetaのMTIA記事との関連——HBM供給問題の現実
昨日の記事(3月26日)でMetaの自社AIチップ「MTIA」を取り上げた際に、HBMの供給不足について触れた。MetaがNVIDIAのGPUから自社チップへの移行を急ぐ理由の一つが、HBMの調達競争の激化だった。
今回のSamsungの発表は、この供給問題にどう影響するか。
短期的には、HBM4Eの量産はまだ先(2027年以降と見られる)のため、現在の供給逼迫を直接解消することはない。だが中長期的には、HCB技術による積層数の増加が、同じウエハ面積からより多くのメモリ容量を生産できることを意味する。つまり製造効率の向上を通じて、供給力の改善に寄与する可能性がある。
一方で、AI需要の増加ペースがメモリ供給の拡大ペースを上回る状況は当面続くだろう。NVIDIA、AMD、Intel、そしてGoogleやMetaのカスタムチップがすべてHBMを必要としており、需要側の圧力は増す一方だ。Samsungの技術革新は歓迎すべきだが、供給問題の「解決」ではなく「緩和」と捉えるのが現実的だ。
GTC 2026でのメモリ技術の位置づけ
NVIDIA GTC 2026では、Jensen Huang CEOが基調講演でAIインフラの次の段階について語った。その中でメモリ技術への言及は少なくなく、NVIDIAがGPUの進化だけでなく、メモリとのインターフェース最適化をシステム設計の中核に据えていることが伝わってきた。
SamsungのHBM4Eがこのタイミングで発表されたのは偶然ではない。NVIDIAのロードマップに合わせて技術をアピールすることで、Vera Rubinの次の世代でも主要サプライヤーとしてのポジションを確保したい——Samsungのそんな意図が透けて見える。
今後の注目ポイント
HBM4Eの量産開始時期が最も重要なマイルストーンだ。技術デモと量産はまったく別物であり、HCB技術を用いた16層以上の積層を安定的に生産できるかが試される。Samsungが2027年前半に量産を開始できれば、SK hynixとの差を縮める大きな一歩になる。
また、HBM4Eの搭載先となるAIアクセラレータの動向も注視すべきだ。NVIDIAのVera Rubin後継プラットフォーム、AMDの次世代Instinct、そしてGoogleやMetaのカスタムチップなど、HBM4E世代を活用する製品が出揃うのは2027年後半以降になるだろう。
メモリはAIの「縁の下の力持ち」だ。GPUのスペック競争ほど派手ではないが、AI産業全体のパフォーマンスとコストを根底から規定している。Samsung、SK hynix、Micronの3社による技術競争が、AIの進化速度そのものを決めていると言っても過言ではない。帯域幅4.0TB/sのHBM4Eが量産に到達したとき、AIは今とは違う速度で動き始める。
Sources:
- Samsung Unveils HBM4E, Showcasing Comprehensive AI Solutions, NVIDIA Partnership and Vision at NVIDIA GTC 2026 | Samsung Global Newsroom
- Samsung Unveils HBM4E Memory: Up To 4 TB/s Bandwidth Per Stack, 16 Gbps & 48 GB Capacity | WCCFTech
- Samsung Electronics Unveils HBM4E at GTC 2026 With 4TB/s Bandwidth | THE ELEC
- Samsung breaks the 16 Gbps barrier with HBM4E reveal at GTC 2026 | NotebookCheck
- Samsung and Micron confirm HBM4 enters mass production for NVIDIA Vera Rubin | VideoCardz