
DeepSeek V4――1兆パラメータのオープンソースAIが業界の前提を書き換える
1兆パラメータ。MIT License。誰でもダウンロードできる。
中国のAIスタートアップ DeepSeek が開発中の大規模言語モデル「DeepSeek V4」が、業界の空気を一変させつつある。正式リリースは2026年4月の見込みだが、3月9日にはコンテキストウィンドウを拡張するサイレントアップデートが確認され、コミュニティでは早くも「V4 Lite」の通称で呼ばれ始めた。GPT-5.4、Claude 4.6、Gemini 3.1といったクローズドなフロンティアモデルと同等の性能を、オープンウェイトで実現しようとしている。
率直に言えば、これはオープンソースAIの歴史における最大級の転換点になりうる。
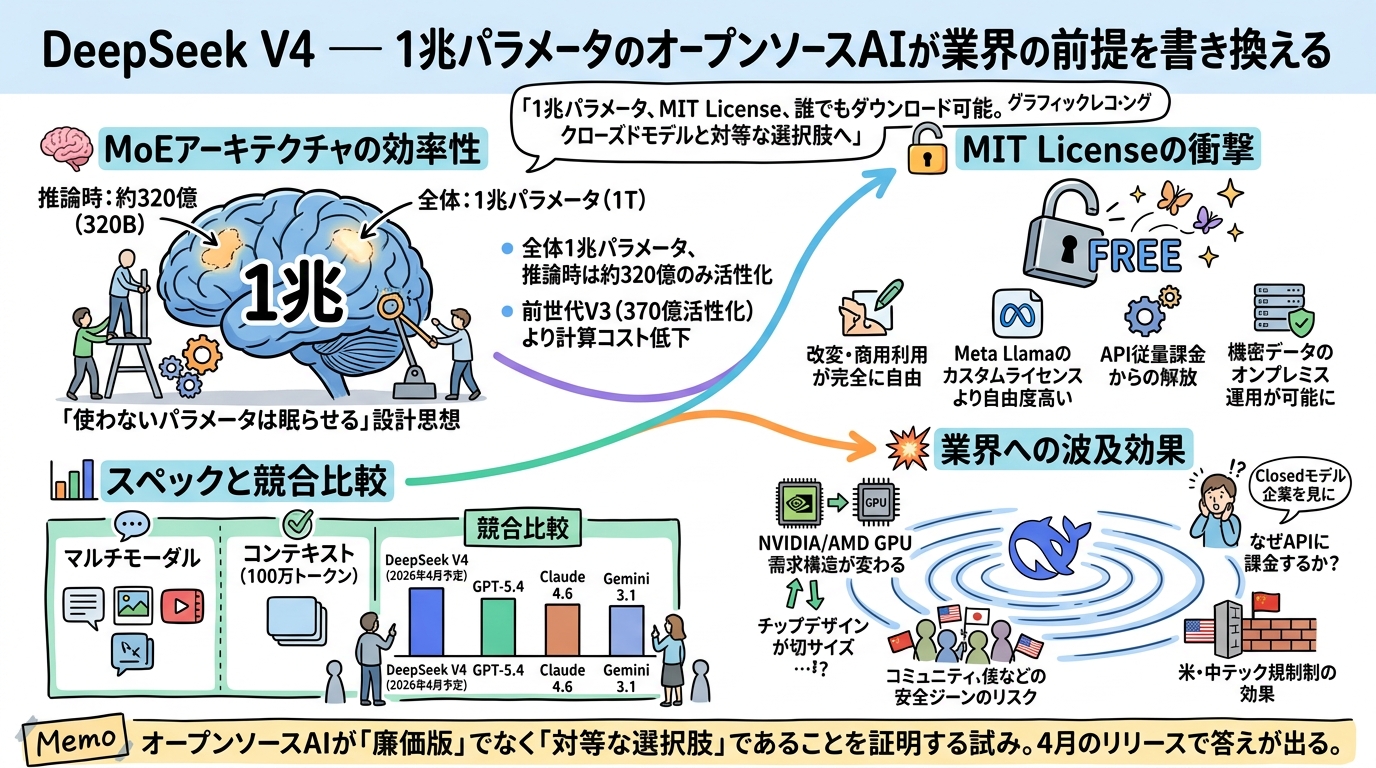
1兆の先にある「効率」という設計思想
1兆パラメータと聞くと、力任せの巨大化を想像するかもしれない。だが DeepSeek V4 の本質はむしろ逆で、「使わないパラメータは眠らせておく」という効率重視の設計にある。
採用されているのは Mixture-of-Experts(MoE)アーキテクチャ。モデル全体は1兆パラメータの規模を持つが、1トークンの処理に実際に動くのは約320億パラメータだけだ。前世代の V3 では370億パラメータが活性化していたから、モデルが大きくなったにもかかわらず推論時の計算コストはむしろ下がっている。
ここで気になるのは、この効率化がどこまで推論品質を維持できているかという点だろう。MoE はルーティングの精度がすべてを左右する。どの「専門家」にトークンを振り分けるかの判断が甘ければ、パラメータ数の帳尻だけ合わせた張りぼてになりかねない。ベンチマーク上はフロンティアモデルと互角とされているが、正式リリース後の独立評価を待ちたいところではある。
マルチモーダルと100万トークン――2つの「当たり前」への回答
2026年のフロンティアモデルに求められる要件は明確になってきた。テキストだけでは足りない。長い文脈を扱えなければ話にならない。DeepSeek V4 はその両方に応えている。
マルチモーダル対応として、テキスト・画像・動画の生成をカバーする。GPT-5.4 や Gemini 3.1 が先行していた領域に、オープンソースモデルとして本格参入した格好だ。
コンテキストウィンドウは100万トークン。 Google の Gemini シリーズと同等の水準で、書籍1冊分に相当するテキストを一度に処理できる計算になる。3月9日のサイレントアップデートでこの拡張が確認された際、Redditや中国のテックフォーラムでは「ついに来た」という反応が相次いだ。中国テックメディア Whale Lab が4月の正式リリースを報じたことで、期待はさらに加速している。
正直なところ、100万トークンのコンテキストを「本当に有効に使い切れるか」は別の問題だ。長文コンテキストでは中間部分の情報が抜け落ちる"Lost in the Middle"問題が知られており、V4 がこれをどの程度克服しているかは注視すべきポイントになる。
MIT License が意味するもの
技術的なスペックと同じくらい重要なのが、ライセンスの選択だ。DeepSeek V4 は MIT License で公開される。
これが何を意味するか。企業は V4 をダウンロードし、自社の用途に合わせて改変し、商用プロダクトに組み込める。帰属表示すら最小限で済む。Meta の Llama シリーズがカスタムライセンスで一部の商用利用に制限をかけていたのと比べると、はるかに自由度が高い。
スタートアップにとっては、API 従量課金から解放される道が開ける。大企業にとっては、機密データを外部 API に送らずに済むオンプレミス運用の選択肢が広がる。研究者にとっては、モデルの内部を自由に調べ、再現実験を回せる環境が手に入る。
もちろん、1兆パラメータのモデルを実際に動かすにはそれなりのインフラが要る。MoE で推論時の計算量は抑えられているとはいえ、モデル全体をメモリに載せるだけでも数百GBクラスの VRAM が必要になる見込みだ。「誰でもダウンロードできる」ことと「誰でも動かせる」ことの間には、まだ距離がある。量子化や蒸留によるコンパクト版が出てくるまでは、真の民主化とは呼びにくい。
NVIDIA・AMD、そしてクローズドモデル勢への波及
DeepSeek のオープンソース戦略は、AI モデルの競争だけにとどまらず、ハードウェアのビジネスモデルにも波紋を投げかけている。
NVIDIA の GPU は AI 訓練・推論の事実上の標準だが、オープンソースモデルの普及はハードウェア需要の構造を変える可能性がある。クラウド API 経由でモデルを利用するなら、エンドユーザーは GPU を気にしなくていい。だが、オープンウェイトのモデルを自前で動かしたい企業が増えれば、GPU の需要層が変わる。データセンター向けの超高価格帯だけでなく、ミッドレンジの推論用アクセラレータにも市場が開けてくるわけだ。AMD にとっては追い風になるかもしれない。
一方、OpenAI や Anthropic、Google のクローズドモデル陣営にとっては、別種のプレッシャーがかかる。「なぜ API に月額料金を払うのか」という問いに対して、性能差だけでは答えにくくなる。安全性のガードレール、エンタープライズサポート、統合エコシステムといった「モデル以外の価値」で差別化する必要性がいっそう高まるだろう。
Meta の Llama、Mistral の各モデル、そして DeepSeek。オープンソース勢がフロンティアモデルの性能に追いつくたびに、クローズドモデルの存在意義が問い直されてきた。V4 はその問いを、過去最大の規模で突きつけている。
見えてきた構図、残された問い
DeepSeek V4 の輪郭を整理しておこう。
- 規模: 1兆パラメータ(MoE、活性化は約320億)
- 対応モダリティ: テキスト、画像、動画
- コンテキスト: 100万トークン
- ライセンス: MIT License(完全オープン)
- 競合: GPT-5.4、Claude 4.6、Gemini 3.1
4月の正式リリースを前に、すでにコミュニティは活発に動いている。サイレントアップデートの解析、ベンチマークの非公式検証、量子化手法の模索。オープンソースの強みは、リリースを待たずとも議論と実験が進むところにある。
ただし、楽観だけでは済まない問題もある。安全性の担保をコミュニティに委ねることのリスク、米中間の技術規制がオープンウェイトの配布に影響する可能性、そして1兆パラメータのモデルを責任ある形で運用するためのガバナンスの枠組み。技術が進むほど、これらの問いは重くなる。
DeepSeek V4 は、オープンソースAIが「クローズドモデルの廉価版」ではなく「対等な選択肢」であることを証明しようとしている。その試みが成功するかどうかの答えは、4月以降に出る。
Sources:
- DeepSeek V4 (2026): 1T Parameters, 81% SWE-bench, $0.30/MTok — Full Specs | NxCode
- DeepSeek V4: Trillion-Parameter Open-Source AI | Digital Applied
- DeepSeek V4 Still Not Out — But Something Appeared on March 9 | LeaveIt2AI
- DeepSeek V4 and Qwen 3.5: Open-Source AI Is Rewriting the Rules in 2026 | Particula
- DeepSeek V4 Status Report: March 2026 Timeline and Technical Specs | PromptZone